
摘要
点击率(CTR)估计是个性化广告和推荐系统中的基本任务。近年来,深度学习模型和注意力机制在计算机视觉(CV)和自然语言处理(NLP)等各种任务中取得了成功。如何将注意力机制与深度CTR模型相结合是一个有前途的方向,因为它可能结合了双方的优势。
尽管已经提出了一些CTR模型,如Attentional Factorization Machine (AFM),用于建模二阶交互特征的权重,但我们认为在明确的特征交互过程之前评估特征重要性也对CTR预测任务很重要,因为如果任务有很多输入特征,模型可以学会有选择地突出显示信息丰富的特征并抑制不太有用的特征。
在本文中,我们提出了一种新的神经CTR模型,名为Field Attentive Deep Field-aware Factorization Machine (FAT-DeepFFM),它将Deep Field-aware Factorization Machine (DeepFFM)与Compose-Excitation网络(CENet)字段注意力机制相结合。
CENet字段注意力机制是由我们提出的,作为Squeeze-Excitation网络(SENet)的增强版本,用于突出显示特征的重要性。我们在两个真实世界的数据集上进行了广泛的实验,实验结果表明,FAT-DeepFFM表现最佳,并在超越现有方法的基础上获得不同程度的改进。我们还比较了两种注意力机制(在明确的特征交互之前的注意力 vs. 在明确的特征交互之后的注意力),并证明前者明显优于后者。
Field Attentive DeepFFM
DeepFFM
我们的工作最初旨在将FFM模型引入神经CTR系统中。然而,类似于我们的工作,杨等人在2017年腾讯社交广告竞赛中也报告了他们的努力。
作者在使用神经FFM后报告了CTR预测系统中的实质性收益。神经FFM在那次竞赛中非常成功:第三名的解决方案基于这个单一模型,而集成版本赢得了竞赛的第一名。
因为很难找到有关这个模型的详细技术描述,所以我们首先介绍神经FFM模型,本文将其称为DeepFFM模型。
众所周知,FM模型[Rendle, 2010]将特征i和j之间的交互建模为它们对应嵌入向量的点积,如下所示:

CENet嵌入矩阵层的领域注意力
胡等人提出了“Squeeze-and-Excitation Network”(SENet)[Hu等人,2017],通过明确建模各种图像分类任务中卷积特征通道之间的相互关系,以提高网络的表示能力。SENet在图像分类任务中表现出色,并赢得了2017年ILSVRC分类任务的第一名。
我们的工作受到了SENet在计算机视觉领域的成功启发。为了提高深度CTR网络的表示能力,我们将Compose-Excitation network(CENet)注意机制引入到DeepFFM模型的嵌入矩阵层中,这是SENet的增强版本。
我们的目标是通过明确建模所有不同特征之间的相互关系,在FM的特征交互过程之前动态捕获每个特征的重要性。我们的目标是使用CENet注意机制执行特征重新校准,通过它可以学会有选择地突出显示信息丰富的特征并抑制不太有用的特征。
从图2可以看出,CENet类似的领域注意机制涉及两个阶段:Compose阶段和Excitation阶段。第一阶段通过将一个嵌入向量的所有信息组合成一个简单的特征描述符,计算每个领域的每个嵌入向量的“摘要统计信息”;第二阶段对这些特征描述符应用注意变换,然后使用计算出的注意力值对原始嵌入矩阵进行重新缩放。

结合领域注意力和DeepFFM
CENet注意机制可以通过进行特征校准来学习选择性地突出显示信息丰富的特征并抑制不太有用的特征。
我们可以通过将CENet注意模块插入其中来增强DeepFFM模型。
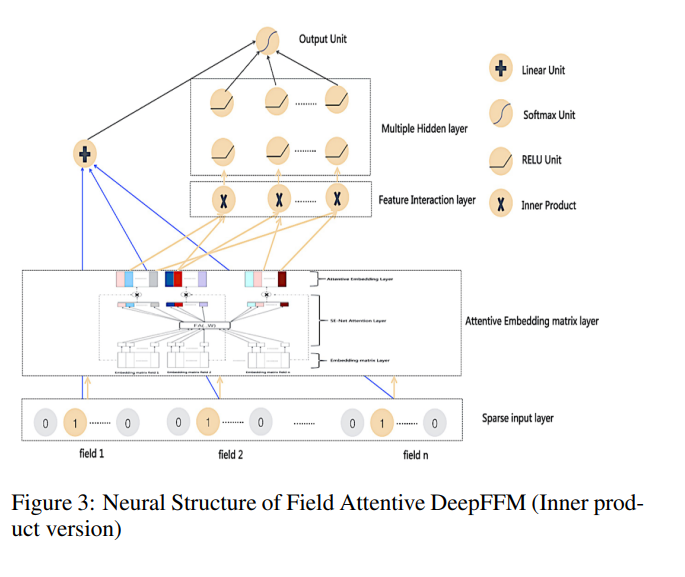
图3提供了我们提出的Field Attentive Deep Field-aware Factorization Machine (FAT-DeepFFM)的整体架构。
它在神经结构上类似于DeepFFM,而原始的嵌入矩阵层被SE-Net类似的领域注意模块替换。我们将这个新插入的模块称为注意嵌入矩阵层。
FAT-DeepFFM的其他组件与DeepFFM模型相同。与DeepFFM一样,根据特征交互类型,FAT-DeepFFM也有两个版本:内积版本和Hadamard积版本。
实验结果
为了全面评估我们提出的方法,我们设计了一些实验来回答以下研究问题:
RQ1:我们提出的FAT-DeepFFM是否能胜过基于深度学习的CTR模型的现有最佳方法?
RQ2:哪种注意机制(在明确特征交互之前对特征进行注意 vs. 在明确特征交互之后对交叉特征进行注意)在真实世界的CTR数据集上表现更好?
RQ3:在基于神经网络的CTR模型中,哪种特征交互方法(内积 vs. Hadamard积)更有效?
实验设置
我们的实验使用了以下两个数据集:
- Criteo1 数据集。作为一个非常著名的公共实际展示广告数据集,其中包含每个广告展示的信息以及相应的用户点击反馈,Criteo 数据集被广泛用于许多CTR模型的评估。Criteo 数据集包含 26 个匿名分类字段和 13 个连续特征字段。我们将数据随机拆分为训练集和测试集,比例为90%:10%。
- Avazu2 数据集。Avazu 数据集包含了连续几天的广告点击数据,按时间顺序排列。对于每次点击数据,有 24 个字段,其中包括广告的信息以及与点击相关的特征。

评估指标
我们的实验中使用了AUC(ROC曲线下面积)和Logloss(交叉熵)作为评估指标。这两个指标在二分类任务中非常常见。
AUC对于分类阈值和正样本比例不敏感。AUC的上限是1,较大的值表示性能更好。Log loss用于衡量两个分布之间的距离,较小的Log loss值表示性能更好。
比较模型
我们将以下CTR估计模型与基线进行性能比较:LR、FM、FFM、FNN、DeepFM、AFM、Deep&Cross Network(DCN)、xDeepFM和DeepFFM,这些模型在第2节和第3节中进行了讨论。
实现细节
我们在实验中使用Tensorflow实现了所有模型。
对于优化方法,我们使用了Adam,迷你批量大小设置为1000,学习率设置为0.0001。
我们在论文中关注神经网络结构,将所有模型的字段嵌入维度设置为固定值10。对于具有DNN部分的模型,隐藏层的深度设置为3,每个隐藏层的神经元数量对于与FFM相关的模型为1600,对于所有其他深度模型为400,所有激活函数都为ReLU,丢弃率设置为0.5。对于CENet组件,激活函数为ReLU,相关实验中的缩减比例设置为1。我们在2个Tesla K40 GPU上进行实验。
模型对比

结论
本文提出了一种新的神经CTR模型,称为“基于字段关注的深度场感知因子分解机”(FAT-DeepFFM),通过将深度场感知因子分解机(DeepFFM)与CENet字段关注机制相结合。我们在两个真实数据集上进行了广泛的实验,
实验结果表明FAT-DeepFFM在性能上表现最佳,并在各方面相对于最先进的方法获得了不同程度的改进。
我们还表明,FAT-DeepFFM在两个数据集上始终优于DeepFFM,这表明当任务涉及许多输入特征时,CENet字段关注机制对于学习原始特征的重要性非常有帮助。
我们还比较了两种不同类型的注意机制(在明确的特征交互之前关注与在明确的特征交互之后关注),实验结果表明前者明显优于后者。
原文link
 微信打赏
微信打赏










