
总结
The paper refers to a technique or approach used in predictive analytics or data science for predicting conversion rates across a broad range of scenarios or situations. Let’s break down this concept:
Conversion Rate Prediction: This part of the phrase refers to the process of estimating or forecasting the likelihood that a user or customer will take a specific desired action, typically on a website or app. This action could be anything from making a purchase to signing up for a newsletter or clicking on an advertisement.
Entire Space: This suggests that the prediction model is not limited to a specific subset of data or scenarios but is designed to work across a wide range of situations or conditions. In other words, it aims to provide predictions for all possible scenarios within a given context.
Delayed Feedback Modeling: This indicates that the model takes into account feedback or information that is not immediately available but may become available over time. In the context of conversion rate prediction, delayed feedback could refer to data that becomes available after a user has taken a specific action. For example, whether a user made a purchase or not might not be known immediately but could become known later.
In practice, delayed feedback modeling for conversion rate prediction could involve the use of advanced machine learning techniques that consider various factors and time-related data to make accurate predictions. It may involve handling incomplete or delayed data and updating predictions as more information becomes available.
This approach is valuable in situations where conversion rates can vary widely across different scenarios or when there is a need to make predictions in real-time while considering the delayed feedback that might impact the final outcome. It’s a sophisticated way to optimize marketing, sales, or user experience strategies in various industries, including e-commerce, online advertising, and more.
摘要
估计后点击转化率(CVR)在电子商务中至关重要。然而,在实际应用中,
CVR预测通常面临三个主要挑战:
i)数据稀缺性:与印象相比,转化样本通常极其稀少;
ii)样本选择偏差:传统CVR模型是基于点击印象进行训练的,而在所有印象的整个空间中进行推断;
iii)延迟反馈:许多转化只能在相对长且随机的延迟后才能观察到,导致训练过程中存在许多虚假负标签。
在本文中,我们提出了一种新颖的神经网络框架ESDF,以同时应对上述三个挑战。与现有方法不同,ESDF从整个空间的角度来建模CVR预测,并结合了用户序列行为模式和时间延迟因素的优势。具体而言,ESDF利用用户在所有印象上的序列行为来减轻样本选择偏差问题。通过共享CTR和CVR网络之间的嵌入参数,数据稀疏性问题得到了很大的缓解。与传统的延迟反馈方法不同,ESDF不对延迟分布做任何特殊假设。我们通过将延迟时间按天时间段离散化,并基于深度神经网络进行生存分析来建模概率,这更实际且适用于工业情境。进行了大量实验证明了我们方法的有效性。据我们所知,ESDF是CV预测领域首次尝试统一解决上述三个挑战的方法。
introduction 介绍
在电子商务搜索和推荐系统中,准确估计点击率(CTR)和转化率(CVR)起着至关重要的作用。它有助于发现有价值的产品并更好地理解用户的购买意图。由于具有巨大的商业价值,已经投入了大量工作来设计智能的CTR和CVR算法。
对于CTR估计,近年来提出了许多先进的模型,如DeepFM、xDeepFM、DIN、DIEN等(Guo等人,2017年;Lian等人,2018年;Zhou等人,2018年,2019年)。通过充分利用深度神经网络的强大非线性拟合能力和大量的点击和印象数据,CTR模型取得了出色的性能。然而,由于标签收集和数据集大小问题,对于CVR建模而言,情况变得相当不同且具有挑战性。
CVR建模的主要困难可以总结为以下三点。
第一个挑战是数据稀缺性。通常,我们使用由点击印象组成的数据集来训练CVR模型,与CTR数据集相比,这个数据集通常要小得多。更糟糕的是,转化通常非常稀缺。数据稀缺性问题使CVR模型很难拟合,通常无法如我们期望的那样获得令人满意的结果。
第二个挑战是样本选择偏差问题,这指的是训练和测试空间之间数据分布的不一致性。传统的CVR模型是基于点击印象进行训练的,但用于对所有印象的整个空间进行推断。这可能会严重损害CVR模型的泛化性能。
最后但同样重要的挑战是转化延迟问题。与点击反馈可以在点击事件发生后立即收集不同,许多转化只能在相对长且随机的延迟后才能观察到,导致CVR数据集中存在许多虚假负标签。例如,用户可能首先将产品添加到购物车或愿望清单中,经过几次比较后,才决定是否付款。这种延迟反馈产生了大量的虚假负样本,并导致对CVR建模的低估。
为了减轻数据稀缺性问题,
(Lee等人,2012年)模型化不同层次的转化事件,采用单独的二项分布,并使用逻辑回归将各个估算器结合起来。然而,这种方法无法应用于具有数以千百万计用户和物品的搜索和推荐系统。
(Su等人,2020年)选择使用预训练的图像模型生成密集的物品嵌入,这在很大程度上受到图像质量的影响。
为了解决样本选择偏差问题,(Pan等人,2008年)通过随机抽样未被点击的印象引入一些负面示例,然而,他们的方法通常导致低估的预测。
(Ma等人,2018年;Wen等人,2020年)利用用户的序列行为图的信息,例如ESMM中的“show → 点击 → 购买”,以及更一般的情况下的“印象 → 点击 → D(O)Action → 购买”。
尽管ESMM和ESM2极大地减轻了数据稀缺性和样本选择偏差的问题,但它们都忽视了转化延迟的问题,这是CVR建模的一个独特挑战。
为了处理时间延迟问题,(Chapelle,2014年)假设时间延迟遵循指数分布,并引入了一个额外的模型来捕捉转化延迟。然而,并没有保证时间延迟遵循指数分布。(Yoshikawa和Imai,2018年)提出了一个更一般的非参数延迟反馈模型,以估计时间延迟,而不需要参数分布假设,但核密度函数的计算过于复杂,无法在工业环境中部署。
在本文中,我们提出了一个从整个空间的角度出发的端到端框架,试图同时解决上述三个挑战。
通过利用用户行为的序列模式,我们采用了一个多任务框架,并构建了CTR和CTCVR两个辅助任务,以消除数据稀缺性和样本选择偏差问题。此外,为了解决时间延迟的挑战,我们设计了一个新颖的时间延迟模型。在没有关于时间延迟分布的特殊假设的情况下,我们使用生存分析的机制来近似这一过程。
具体来说,我们将延迟时间转化为离散的日时间段,并通过预测转化将落入哪个时间段来近似生存概率。目标优化通过最大化数据集的对数似然进行。
本文的主要贡献总结如下:
• 我们从整个空间的角度结合了用户序列行为模式和时间延迟因素的优势,提出了一种新颖的ESDF框架,同时解决了CVR预测的数据稀缺性、样本选择偏差和时间延迟挑战。
• 在没有任何特殊分布假设的情况下,ESDF将延迟时间转化为离散的时间段,并通过生存分析机制来近似延迟过程,这更加通用和实际。
• 我们在工业数据集上进行了大量实验,以展示ESDF的有效性。据我们所知,这是首次尝试统一解决上述三个挑战。此外,我们发布了一个用于未来研究的样本数据集,这是首个包含用户序列行为和整个空间上的时间延迟信息的公共数据集。
算法
在本节中,我们将介绍我们的神经网络框架ESDF,
它包括两个主要部分:转化模型部分和时间延迟模型部分。
整个神经网络框架如图1所示。

为了更好地解释,我们总结了ESDF所使用的变量符号的表示方式.
在接下来的部分中,我们将把我们的模型分成三个模块。
在第一部分,我们将详细解释我们的转化模型的细节以及我们如何处理数据稀缺性和样本选择偏差问题。
在第二部分,我们将描述如何构建时间延迟模型的细节,以及与其他时间延迟模型的区别。
通过将转化和时间延迟模型结合在一起,我们将在最后一部分介绍我们的方法。
转化模型
转化模型的目标是估计 pCVR = P(C = 1|Y = 1, X = x, E = e) 的概率。
与许多以前的工作类似,如(Chapelle,2014年;Su等人,2020年),我们假设:
P(C|Y = 1, X, E) = P(C|Y = 1, X)(1)
这是有道理的,因为自点击以来经过的时间通常不会对最终的转化产生任何影响。
为了消除样本选择偏差和数据稀缺性问题,我们借鉴了ESMM和ESM2的思想(Ma等人,2018年;Wen等人,2020年)。通过利用用户行为的顺序模式“印象 → 点击 → 付款”,我们一起构建了CTR和后视图点击通过和转化率(CTCVR)任务。在这里,我们使用pCTR和pCTCVR分别表示CTR和CTCVR的概率,
其中pCTR = P(Y = 1|X = x)和pCTCVR = P(C = 1, Y = 1|X = x)。
然后,第i个样本的CVR预测可以表示为:
P(ci = 1|yi = 1, xi) = P(ci = 1, yi = 1|xi) P(yi = 1|xi)(2)
从方程2可以看出,P(ci = 1, yi = 1|xi)和P(yi = 1|xi)都可以在整个输入空间X上建模,这极大地有助于缓解样本选择偏差问题。在大多数情况下,点击率很低,所以P(ci = 1|yi = 1, xi)可能大于1,并可能导致数值不稳定性。
因此,我们同时建模pCTR和pCTCVR。这有助于我们避免数值不稳定性的问题。
此外,我们能够使用所有CTR样本进行建模,这有助于我们获得更稳定的训练过程和更好的性能,因为CTR样本的大小远远大于CVR样本的大小。在我们的神经网络框架中,嵌入层是共享的,这使得CVR网络能够从大量的CTR样本中学习,并极大地减轻了数据稀缺性问题。与(Ma等人,2018年;Wen等人,2020年)不同,我们添加了时间延迟模型,试图解决反馈延迟问题。
时间延迟模型
为了解决反馈延迟的问题,我们参考了生存分析(Jr. 2011)的思想来建模时间延迟。生存分析最初用于分析直到一个或多个事件发生的预期持续时间。对应我们的问题,这里的”事件”可以被视为转化。我们用f(t)表示概率密度函数,表示在时间t时发生转化的概率。然后我们可以得到生存函数:
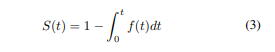
为了使我们的模型更通用并适用于不同的场景,我们不会对分布做任何特殊的假设,比如指数分布(Chapelle,2014年)或Weibull分布(Ji,Wang和Zhu,2017年)。相反,我们选择利用用户、物品和上下文的特征来构建时间延迟模型,这更加合理,容易推广到其他场景。
在我们的算法中,我们首先通过时间段来转换延迟时间。具体来说,延迟时间被分成T + 2个区间。i ≤ T的第i个区间表示转化在点击后i天发生,T +1表示转化的延迟时间大于T天。这是相当合理的,因为当T很大时,转化只占一小部分,可以被视为噪音。
因此,我们将所有在点击后T天后发生的转化都放入T +1区间。转化在点击后t天发生的概率可以描述为:
P(D = t|C = 1, Y = 1, E = e, x) = F(g(x, e), t)(4)
其中g(x, e)表示时间延迟模型的softmax输出,F(·, t)是g(x, e)的第t个值,t ∈ [0, T + 1]。为简化起见,我们将在以下内容中使用f(t, x, e)来表示F(g(x, e), t)。
实验
在本节中,我们将展示我们所提出的方法的实证研究。实验的主要目的是阐明我们的算法的两个特点。
• 有效性:我们提出的ESDF模型同时解决了数据稀缺性、样本选择偏差和时间延迟问题。为了验证我们模型的有效性,我们进行了大量实验,以展示ESDF在所有比较方法中可以获得可比较的性能。
• 时间延迟模型的优越性:通过将延迟时间离散化并利用深度神经网络的表示能力,ESDF是工业情境下更通用和实用的解决方案。我们通过与不同类型的时间延迟处理方法进行比较,展示了时间延迟模型的优越性。
数据集
根据我们的调查,这是第一次在整个空间上对延迟反馈进行CVR预测建模。大多数相关数据集是在后点击阶段收集的,
例如(Chapelle,2014年)中使用的经典criteo数据集,或者缺乏延迟信息,如(Ma等人,2018年)。
在CVR建模领域,没有公共数据集同时包含印象、点击和转化标签。
为了评估所提出的方法并更好地研究这个问题,我们从我们的电子商务搜索系统中收集了流量日志,并开放了整个数据集的简化随机抽样版本。
在本文的其余部分,我们将发布的数据集称为公共数据集,将整个数据集称为产品数据集。这两个数据集的统计信息总结在表2中。训练数据由2020年05月30日至2020年06月05日期间的日志组成,而测试数据包括2020年06月06日期的数据。
对于延迟转化样本,我们将归因窗口设置为7天。
因此,测试数据的转化标签已被归因到2020年06月12日,而训练数据的标签只能被归因到2020年06月05日。这与实际的生产环境一致,因为我们无法观察未来的信息
。如图2所示,
大约80%的转化发生在第一天,但其余的转化发生得晚得多。这意味着如果我们采用传统的一天内的标签收集范例,我们可能会错误地将20%的正样本误认为负样本。训练数据和测试数据之间存在轻微的分布差异。这是因为测试数据是用地面真实的转化标签标记的。数据集的更详细描述可以在URL1的网站上找到。
实验设置
ROC AUC(Fawcett,2006年)是CVR预测任务中广泛使用的指标,它表示随机正样本被排名高于负样本的概率。在(He和McAuley,2016年;Zhu等人,2017年)中引入了一种变种的组内AUC(GAUC),它通过对用户进行AUC平均来测量用户内部顺序的项目,并且在CVR预测的在线性能上更相关。在本文中,我们按照每个用户的请求对印象进行分组,以计算GAUC:

其中N是用户请求的数量,AUCi对应于第i个请求的排名模型的性能。值得注意的是,对于具有相同标签的一组样本,GAUC的值为0.5。在计算GAUC时,我们只考虑实际中包含正样本和负样本的组。此外,我们按照(Yan等人,2014年)的方法引入RelaImpr来衡量相对于基线模型的相对改进。RelaImpr定义如下:

比较方法
为了验证我们的延迟反馈框架的有效性,我们选择以下基线进行比较。为了保证公平性,我们重新使用深度神经网络实现了所有方法。所有基线都在CTR和CVR任务之间共享嵌入。
• ESMM(Ma等人,2018年):ESMM通过在整个空间上建模CVR来消除数据稀缺性和选择偏差问题。在这里,我们将其用作基线框架。与(Chapelle,2014年)中的基线方法一样,其中在第一天未观察到转化的样本被视为负样本。这是实际中处理工业数据的传统范例。
• NAIVE:为了评估假负样本的影响,我们从训练集中删除了它们,并构建了一个与ESMM相同模型的朴素竞争者。
• SHIFT:SHIFT将归因窗口从一天扩展到七天。假负样本逐渐在每天根据我们能观察到的最新日期进行修正。这种方法部分修复了假负标签,但不考虑经过的时间和延迟分布。
• DFM(Chapelle,2014年):作为一个强有力的竞争者,DFM考虑了时间延迟的延迟反馈,假定时间延迟服从指数分布。许多基于危险函数逼近的方法最终在假定危险函数与经过的时间独立时退化为DFM。为了公平比较,我们将DFM的逻辑回归替换为深度神经网络,并在CTR和CVR网络之间添加嵌入共享。新版本的DFM与我们的方法具有相同的网络骨干。
参数设置
对于所有实验,嵌入的维度设置为8,批量大小为1024。我们使用Adam(Kingma和Ba,2014年)求解器,初始学习率为0.0001。所有模型的CTR和CVR分支共享相同的MLP架构,为512×256×128×1。ReLU被用作激活函数。时间延迟离散化的槽数设置为7。我们使用相同的超参数在公共数据集和产品数据集上报告所有结果。
ESDF的有效性
公共数据集和产品数据集上的实验结果如表3所示。

请注意,对于公共数据集,由于随机抽样,来自同一请求的印象很稀疏,并且个别请求的GAUC将坍缩为0.5。因此,我们在公共数据集上采用ROC AUC作为指标,在产品数据集上采用GAUC。
从表3中可以看出,ESDF在公共数据集和产品数据集中都优于其他竞争对手,并在ESMM基线上实现了几乎0.08的绝对GAUC增益和6.68%的RelaImpr,对于我们的应用来说,这被认为是相当大的改进。
结论
在本文中,
我们提出了一种新颖的神经网络框架,统一解决了CVR预测中的数据稀缺性、样本选择偏差和反馈延迟挑战。
与现有方法不同,ESDF从整体空间的角度对CVR预测进行建模,结合了用户顺序行为模式和时间延迟因素的优势。
在没有特殊分布假设的情况下,ESDF通过以日时间槽离散化延迟时间并基于生存分析模拟概率,避免了复杂的积分计算,对实际应用友好。
我们进行了大量实验来评估我们方法的有效性,并发布了一个供未来研究使用的公共数据集。需要研究更系统的方法,以从统一的角度解决这些挑战。
 微信打赏
微信打赏









