总结
Multi-Task Learning (MTL) is a widely-used approach in recommendation systems. However, traditional MTL models often encounter challenges in handling complex and competing task correlations within real-world recommender systems. To address these issues, the authors propose the PLE model, which introduces a novel sharing structure.
The PLE model explicitly separates shared components and task-specific components. It incorporates a progressive routing mechanism to gradually extract and differentiate deeper semantic knowledge. This enhances the efficiency of joint representation learning and information routing across tasks in a general setting.
The authors applied PLE to tasks with varying levels of complexity and correlations, including two-task and multi-task scenarios, using a real-world Tencent video recommendation dataset with a billion samples. Results demonstrate that PLE outperforms state-of-the-art MTL models across different task correlations and task-group sizes.
Moreover, online evaluation on a large-scale content recommendation platform at Tencent shows that PLE leads to a 2.23% increase in view-count and a 1.84% increase in watch time compared to existing MTL models. This signifies a significant improvement and validates the effectiveness of PLE in real-world applications.
Additionally, extensive offline experiments on public benchmark datasets confirm that PLE can be applied to various scenarios beyond recommendations, mitigating the “seesaw phenomenon.” PLE has been successfully deployed in Tencent’s online video recommender system.
In summary, the PLE model represents a significant advancement in Multi-Task Learning for personalized recommendations, offering improved performance, efficiency, and practical applicability in real-world recommendation systems.
摘要
多任务学习(MTL)已成功应用于许多推荐系统应用中。然而,MTL 模型通常在真实世界的推荐系统中面临性能下降的问题,这是由于复杂和竞争的任务相关性造成的负面传递效应。此外,通过对各种领先的 MTL 模型进行广泛实验,研究人员观察到一个有趣的现象,即一项任务的性能往往通过损害其他任务的性能来提高。
为了解决这些问题,他们提出了一种名为”Progressive Layered Extraction(PLE)” 的模型,该模型具有新颖的共享结构设计。
PLE 明确分离了共享组件和任务特定组件,并采用渐进式路由机制逐渐提取和分离更深层次的语义知识,从而提高了通用设置中跨任务的联合表示学习和信息路由的效率。
他们将 PLE 应用于复杂相关和正常相关的任务,从两个任务到亿级样本的多任务场景都进行了实验。
结果显示,PLE 在不同任务相关性和任务组大小下明显优于领先的 MTL 模型。此外,在腾讯的大规模内容推荐平台上进行的在线评估表明,与领先的 MTL 模型相比,PLE 在观看次数上增加了 2.23%,观看时间增加了 1.84%,这是一项显著的改进,证明了 PLE 的有效性。
最后,在公共基准数据集上进行的广泛离线实验表明,PLE 可以应用于除推荐之外的各种场景,以消除” 秋千效应”。目前,PLE 已成功部署在腾讯的在线视频推荐系统中。
这一研究的主要贡献是提出了 PLE 模型,它通过改进任务相关性处理方法,提高了多任务学习模型的性能,特别是在大规模推荐系统中的应用。PLE 的在线评估和离线实验结果都表明了它的有效性和实用性。
introduction 介绍
个性化推荐在在线应用中发挥了关键作用。推荐系统(RS)需要整合各种用户反馈,以建模用户兴趣,最大化用户参与度和满意度。然而,由于问题的高维性,通常难以通过学习算法直接解决用户满意度问题。与此同时,用户满意度和参与度有许多可以直接学习的主要因素,例如点击、完成、分享、收藏和评论的可能性等等。因此,越来越多的趋势是在 RS 中应用多任务学习(MTL),以同时建模用户满意度或参与度的多个方面。实际上,这已经成为主要的行业应用方法 [11, 13, 14, 25]。
MTL 在一个单一模型中同时学习多个任务,并已被证明通过任务之间的信息共享提高了学习效率 [2]。然而,在现实世界的推荐系统中,任务通常松散相关甚至存在冲突,这可能导致性能下降,即所谓的负迁移 [21]。通过在实际大规模视频推荐系统和公共基准数据集上进行广泛的实验,我们发现,现有的 MTL 模型通常会在任务之间进行权衡,改善某些任务的性能,但会牺牲其他任务的性能,特别是在任务相关性复杂且有时依赖样本的情况下,多个任务无法同时提高,与相应的单一任务模型相比,这被称为本文中的” 秋千现象”。
以往的研究更多地致力于解决负迁移问题,但忽视了秋千现象,例如,交叉织线网络 [16] 和水门网络 [18] 提出了学习静态线性组合来融合不同任务的表示,但不能捕捉样本依赖性。MMOE [13] 应用门控网络来基于输入组合底层专家以处理任务差异,但忽略了专家之间的差异和交互,我们在工业实践中证明会受到秋千现象的影响。因此,设计一个更强大和高效的模型来处理复杂的相关性并消除具有挑战性的秋千现象至关重要。
为了实现这一目标,我们提出了一种新颖的多任务学习模型,称为渐进分层提取(PLE),它更好地利用了先前的知识来设计共享网络,以捕捉复杂的任务相关性。与 MMOE 中粗略共享的参数相比,PLE 明确地分离了共享和任务特定的专家,以减轻通用知识和任务特定知识之间的有害参数干扰。此外,PLE 引入了多层专家和门控网络,并应用渐进分离路由来从较低层专家中提取更深层次的知识,并逐渐分离高层次的任务特定参数。
为了评估 PLE 的性能,我们在真实的工业推荐数据集以及包括人口收入 [5]、合成数据 [13] 和 Ali-CCP 在内的主要公共数据集上进行了广泛的实验。
实验结果表明,PLE 在所有数据集上表现优于最先进的多任务学习模型,在具有复杂相关性的任务组和在不同场景中具有正常相关性的任务组上都展现出一致的改进。此外,在腾讯的大规模视频推荐系统上的在线指标显著提高,证明了 PLE 在真实世界的推荐应用中的优势。
本文的主要贡献总结如下:
・通过在腾讯的大规模视频推荐系统和公共基准数据集上进行广泛实验,我们观察到了一个有趣的秋千现象,即最先进的多任务学习模型通常会在某些任务上取得改进,但会以牺牲其他任务的性能为代价,并且由于复杂的固有相关性,它们无法超越相应的单一任务模型。
・我们提出了一种具有新颖的共享学习结构的 PLE 模型,旨在从联合表示学习和信息路由的角度提高共享学习效率,进而解决秋千现象和负迁移问题。除了推荐应用外,PLE 还可以灵活应用于各种场景。
・我们进行了大量的离线实验,以评估 PLE 在工业和公共基准数据集上的有效性。在腾讯作为全球最大的内容推荐平台之一进行的在线 A/B 测试结果还表明,PLE 在真实世界应用中相对于最先进的多任务学习模型取得了显著的改进,观看次数增加了 2.23%,观看时长增加了 1.84%,这产生了显著的业务收入。PLE 已成功部署到推荐系统中,并有潜力应用于许多其他推荐应用中。
相关工作: 多任务学习在推荐系统中的应用
为了更好地利用各种用户行为,多任务学习已被广泛应用于推荐系统,并取得了显著的改进。一些研究将传统的推荐算法,如协同过滤和矩阵分解,与 MTL 相结合。例如,卢等人 [11] 和王等人 [23] 对为推荐任务和解释任务学习的潜在表示施加正则化,以共同优化它们。王等人 [22] 将协同过滤与 MTL 相结合,以更高效地学习用户 - 物品相似性。与本文中的 PLE 相比,这些基于因子分解的模型表现出较低的表达能力,无法充分利用任务之间的共性。
作为最基本的 MTL 结构,硬参数共享已被应用于许多基于深度神经网络的推荐系统。ESSM [14] 引入了 CTR(点击率)和 CTCVR 两个辅助任务,并在 CTR 和 CVR(转化率)之间共享嵌入参数,以提高 CVR 预测的性能。Hadash 等人 [7] 提出了一个多任务框架,同时学习排名任务和评分任务的参数。[1] 中的文本推荐任务通过在底层共享表示进行改进。然而,硬参数共享通常在任务之间松散或复杂的相关性下容易出现负迁移和秋千现象。相比之下,我们提出的模型引入了一种新颖的共享机制,以实现更高效的信息共享。
除了硬参数共享外,一些推荐系统应用了具有更高效共享学习机制的 MTL 模型,以更好地利用任务之间的相关性。陈等人 [3] 利用分层多指针共注意力 [20] 来提高推荐任务和解释任务的性能。然而,每个任务的塔状网络在模型中共享相同的表示,这可能仍然会受到任务冲突的影响。应用 MMOE [13] 通过不同的门控网络将共享的专家组合起来,YouTube 视频推荐系统在 [25] 中可以更好地捕捉任务差异并高效优化多个目标。与将所有专家一视同仁的 MMOE 不同,本文中的 PLE 明确地分离了任务共同和任务特定的专家,并采用了一种新颖的渐进分离路由,在真实世界的视频推荐系统中实现了显著的改进,超越了 MMOE。
多任务学习在推荐中的秋千现象
负迁移是多任务学习中常见的现象,特别是对于松散相关的任务 [21]。对于复杂的任务相关性,尤其是样本依赖的相关性模式,我们还观察到了秋千现象,即对于当前的多任务学习模型,改进共享学习效率并在所有任务上实现显著改进,特别是超越相应的单一任务模型,对于这些复杂任务相关性来说是困难的。在本节中,我们将基于腾讯的大规模视频推荐系统介绍并深入研究秋千现象。
用于视频推荐的 MTL 排名系统
在这一小节中,我们简要介绍为腾讯新闻提供服务的 MTL 排名系统,它是全球最大的内容平台之一,根据各种用户反馈向用户推荐新闻和视频。
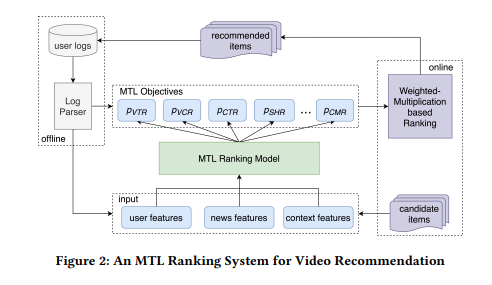
如图 2 所示,MTL 排名系统有多个目标,用于建模不同的用户行为,如点击、分享和评论。在离线训练过程中,我们根据用户日志中提取的用户行为来训练 MTL 排名模型。在每个在线请求之后,排名模型为每个任务输出预测值,然后基于加权乘法的排名模块通过在方程 1 中显示的组合函数将这些预测分数组合成最终分数,最终向用户推荐排名靠前的视频。

其中每个 w 确定了每个预测分数的相对重要性,f (video_len) 是一个非线性变换函数,如视频持续时间中的 sigmoid 或对数函数。wV T R、wV CR、wSH R、wCMR 通过在线实验搜索进行优化,以最大化在线指标。
在所有任务中,VCR(观看完成率)和 VTR(观看通过率)是两个重要的目标,分别建模了观看次数和观看时长的关键在线指标。具体来说,
VCR 预测是一个回归任务,使用均方误差损失进行训练,以预测每个观看的完成比例。VTR 预测是一个二进制分类任务,使用交叉熵损失进行训练,以预测有效观看的概率,有效观看被定义为播放操作超过某个观看时间阈值的情况。VCR 和 VTR 之间的相关模式是复杂的。
首先,VTR 的标签是播放操作和 VCR 的耦合因素,因为只有观看时间超过阈值的播放操作才会被视为有效观看。
其次,播放操作的分布更加复杂,因为来自 WIFI 的自动播放场景的样本具有更高的平均播放概率,而来自没有自动播放的显式点击场景的其他样本具有较低的播放概率。由于复杂且强烈依赖样本的相关模式,当联合建模 VCR 和 VTR 时观察到秋千现象。
多任务学习中的秋千现象
为了更好地理解秋千现象,我们在我们的排名系统中对 VCR 和 VTR 之间复杂相关的任务组使用了单一任务模型和最先进的多任务学习模型进行实验分析。除了硬参数共享、交叉织线 [16]、水门网络 [18] 和 MMOE [13],我们还评估了两种创新提出的结构,分别称为不对称共享和定制共享:
・不对称共享是一种捕捉任务之间不对称关系的新型共享机制。根据图 1b),底层在任务之间不对称共享,共享哪个任务的表示取决于任务之间的关系。可以应用常见的融合操作,如串联、求和池化和平均池化,来组合不同任务的底层输出。
・定制共享如图 1c) 所示,明确分离了共享参数和任务特定参数,以避免固有的冲突和负迁移。与单一任务模型相比,定制共享添加了一个共享底层来提取共享信息,并将共享底层和任务特定层的串联馈送到相应任务的塔状层中。
渐进分层提取
为了解决秋千现象和负迁移问题,我们在本节中提出了一个具有新颖共享结构设计的渐进分层提取(PLE)模型。
首先,我们提出了一个定制门控控制(CGC)模型,明确分离了共享和任务特定的专家。
其次,CGC 被扩展成一个通用的 PLE 模型,具有多级门控网络和渐进分离路由,以实现更高效的信息共享和联合学习。最后,损失函数被优化,以更好地处理多任务学习模型的联合训练中的实际挑战。

实验
在本节中,我们在腾讯的大规模推荐系统和公共基准数据集上进行了广泛的离线和在线实验,以评估所提出模型的有效性。我们还分析了所有基于门控的多任务学习模型中的专家利用情况,以更好地理解门控网络的工作机制,并进一步验证了 CGC 和 PLE 的结构价值。
在腾讯视频推荐系统上的评估
在这一小节中,我们对腾讯视频推荐系统中具有复杂和正常相关性以及多个任务的任务组进行了离线和在线实验,以评估所提出模型的性能。
数据集。
我们通过在为腾讯新闻提供服务的视频推荐系统中连续 8 天的采样用户日志来收集一个工业数据集。数据集中包括 46.926 百万用户、2.682 百万视频和 9.95 亿个样本。如前所述,数据集中的任务包括 VCR、CTR、VTR、SHR(分享率)和 CMR(评论率),用于建模用户的偏好。
基线模型。
在实验中,我们将 CGC 和 PLE 与单一任务模型、不对称共享、定制共享以及包括交叉织线网络、水门网络和 MMOE 在内的最先进多任务学习模型进行比较。由于 PLE 共享了多层专家,我们通过在 ML-MMOE(多层 MMOE)中添加多层专家来扩展 MMOE,如图 1h) 所示,以进行公平比较。在 ML-MMOE 中,高级专家通过门控网络组合来自低级专家的表示,并且所有门控网络共享相同的选择器。
实验设置。
在实验中,VCR 预测是一个回归任务,使用 MSE 损失进行训练和评估,模拟其他动作的任务都是二进制分类任务,使用交叉熵损失进行训练,使用 AUC 进行评估。前 7 天的样本用于训练,其余的样本用作测试集。
我们采用一个三层 MLP 网络,使用 RELU 激活函数,每个任务的隐藏层大小为 [256, 128, 64],在 MTL 模型和单一任务模型中都是如此。
对于 MTL 模型,我们将专家实现为单层网络,并调整以下模型特定的超参数:
共享层数、硬参数共享和交叉织线网络中的交叉单元、所有基于门控的模型中的专家数量。
为了公平比较,我们将所有多级 MTL 模型都实现为两级模型,以保持网络的深度相同。

专家利用分析
为了揭示不同门控如何聚合专家,我们调查了工业数据集中 VTR/VCR 任务组中基于门控模型的所有专家利用情况。
为了简化和公平比较,我们将每个专家视为单层网络,在 CGC 和 PLE 的每个专家模块中仅保留一个专家,而在 MMOE 和 ML-MMOE 的每个层中保留三个专家。
图 8 显示了在所有测试数据中每个门控使用的专家权重分布,其中柱子的高度和垂直短线表示权重的均值和标准差。
图表显示,在 CGC 中,VTR 和 VCR 组合的专家具有明显不同的权重,而在 MMOE 中,权重差异较小,这表明 CGC 的良好设计结构有助于实现不同专家之间更好的差异化。
此外,在 MMOE 和 ML-MMOE 中,所有专家的权重都不为零,这进一步表明,实际中,MMOE 和 ML-MMOE 很难在没有先验知识的情况下收敛到 CGC 和 PLE 的结构,尽管理论上存在可能性。与 CGC 相比,PLE 中的共享专家对于塔状网络的输入影响更大,特别是对于 VTR 任务。PLE 表现优于 CGC 表明了共享的更高级别的深层表示的价值。换句话说,需要在任务之间共享某些更深层次的语义表示,因此渐进分离路由提供了更好的联合路由和学习方案。

结论
在本文中,我们提出了一种新颖的多任务学习模型,称为渐进分层提取(PLE)。
PLE 明确分离了任务共享和任务特定参数,并引入了创新的渐进路由方式,以避免负迁移和秋千现象,并实现更高效的信息共享和联合表示学习。
在工业数据集和公共基准数据集上的离线和在线实验结果显示,PLE 相对于 SOTA 多任务学习模型取得了显著且一致的改进。探索分层任务组的相关性将是未来工作的重点。
paper 链接

 微信打赏
微信打赏